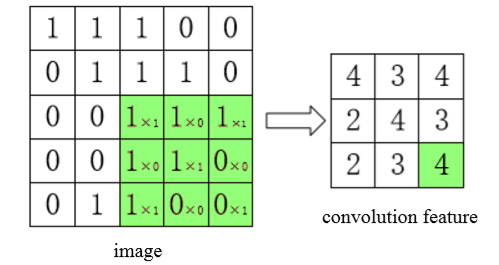
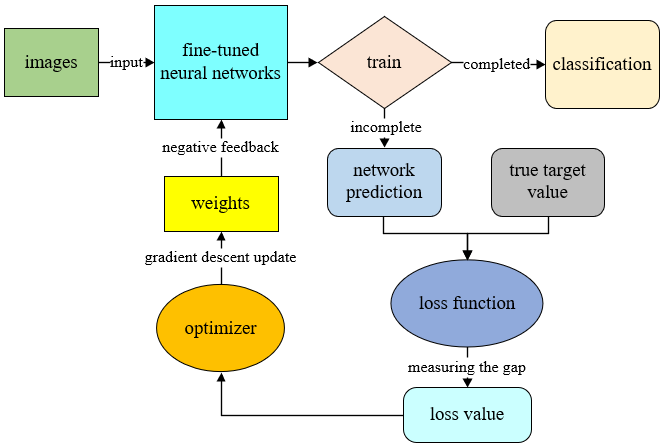
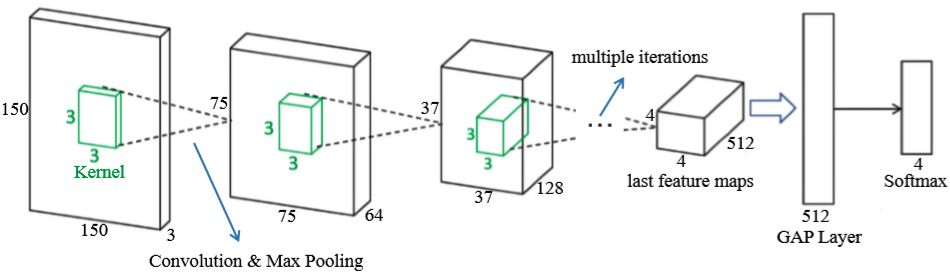
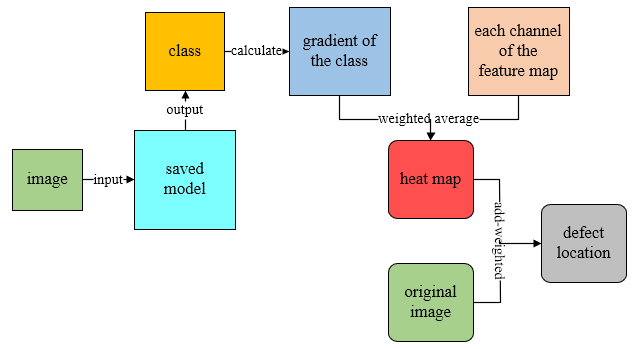
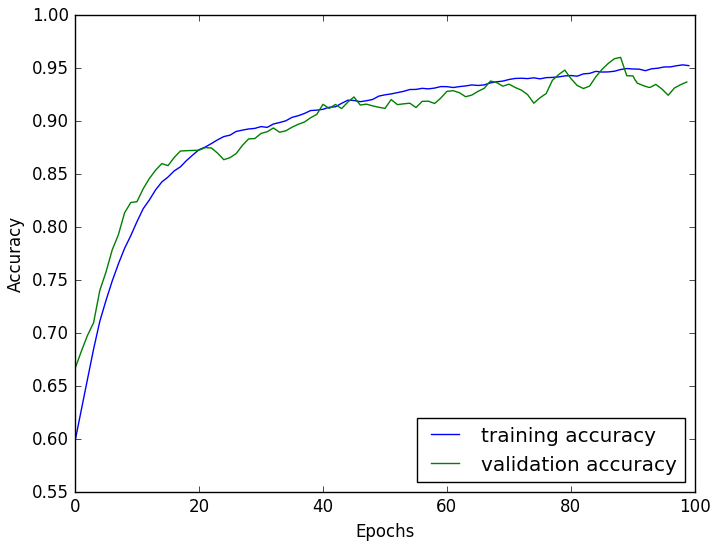
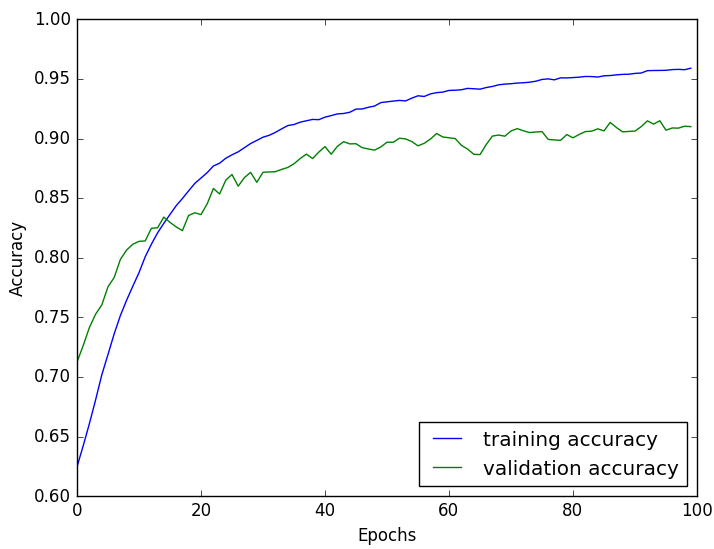
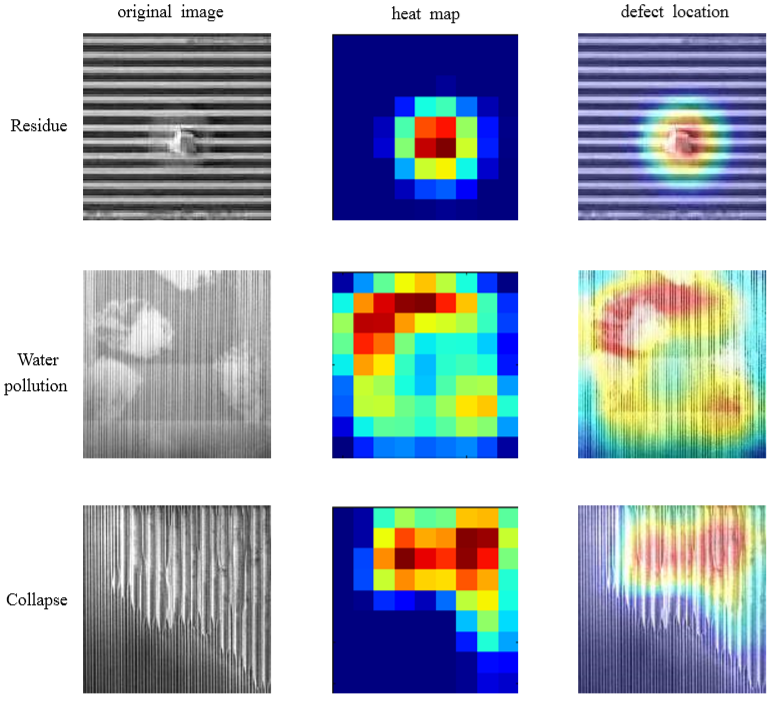
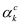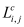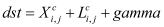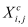The core optimization algorithm of neural network is Backpropagation (BP). Because the neural network has too many layers, it is necessary to pass the network loss layer by layer from the output to the input through the BP algorithm, and update the network parameters in real time
[15]. This needs to pass the decreasing loss value to the optimizer, and update the weight of the network in the reverse direction, so that the network gradually optimizes its own performance, and then realizes the negative feedback of the network.
The specific principle of BP algorithm is gradient descent, so that the network loss value continuously converges to the global (or local) minimum. Since the gradient direction is the fastest direction in which the loss value increases, the negative gradient direction is the fastest direction in which the loss value decreases. Iterate step by step along the direction of the negative gradient to quickly converge to the minimum. This is the basic principle of the gradient descent method.
The loss function is a feedback signal used to learn the weight tensor. In the training phase, the smaller the loss value, the smaller the interval between the network predicted value and the true mark of the sample, and the stronger the model's ability to fit the data. It is an important indicator to measure the degree of match between the predicted value of the network and the true value. This model uses Cross Entropy Loss Function to calculate the cross-entropy loss through the probability output of the predicted class and the one-hot encoding of the true class. The function realization process can be expressed by the following:

(2)
In the formula, L represents the average of the loss value Li of i samples, M represents the number of classes, yic is the symbolic variable (0 or 1, if the class is the same as the sample i, then 1 is taken, otherwise it is 0), pic represents the sample i belongs to the predicted probability of class c.
The optimizer used in this model is RMSprop, which has been proven to be an effective and practical deep learning network optimization algorithm. It combines the exponential moving average of the gradient square to adjust the change of the learning rate, thereby adaptively adjusting the gradient size in each direction, which can help the network to converge well when the loss function is unstable:

(3)
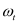
represents the weight at time
t,
α represents the learning rate, the default value is 0.001,
gt represents the gradient at time
t,
vt represents the exponential moving average of the gradient square,
\(\epsilon \) is a constant and the value is 10
-8 to avoid the divisor being 0.
Since the indicator is the ultimate manifestation of the model output purpose, and the model deals with is the classification problem, the indicator is classification accuracy.